
I spent seven years at Turbonomic — back when it was still called VMTurbo, through the rebranding, through the IBM acquisition in 2021, and a few years past that. So writing about autoscaling without touching what I actually worked on every day would feel dishonest. This is the insider perspective: what Turbonomic actually does, why the economic model it's built on is genuinely clever, and where the edges of that model sit.
In Part 1, I laid out the case for why reactive autoscaling falls short and what ML-based approaches bring to the table. Now I want to get more concrete — specifically through the lens of a platform I know well from the inside. Turbonomic (now IBM Turbonomic) takes a different philosophical stance than most scaling tools, and understanding that stance helps clarify what's genuinely novel in the ML-for-autoscaling space and what's been done in production for longer than people often realize.
A quick shoutout here to my former colleague Dr. Debasish Banerjee, who wrote a really solid technical explainer on how Turbonomic's probe architecture works from an IBM developer perspective. Some of what I cover on probes draws from that work and from things we discussed at the time. Good stuff.
The Idea That Made Turbonomic Different
Most autoscalers — cloud-native or otherwise — are fundamentally threshold-following machines. Watch a metric. Cross a line. Take an action. That's a reasonable engineering decision, but it has a structural problem: it treats resource allocation as a local, reactive problem when it's actually a global, continuous-optimization problem.
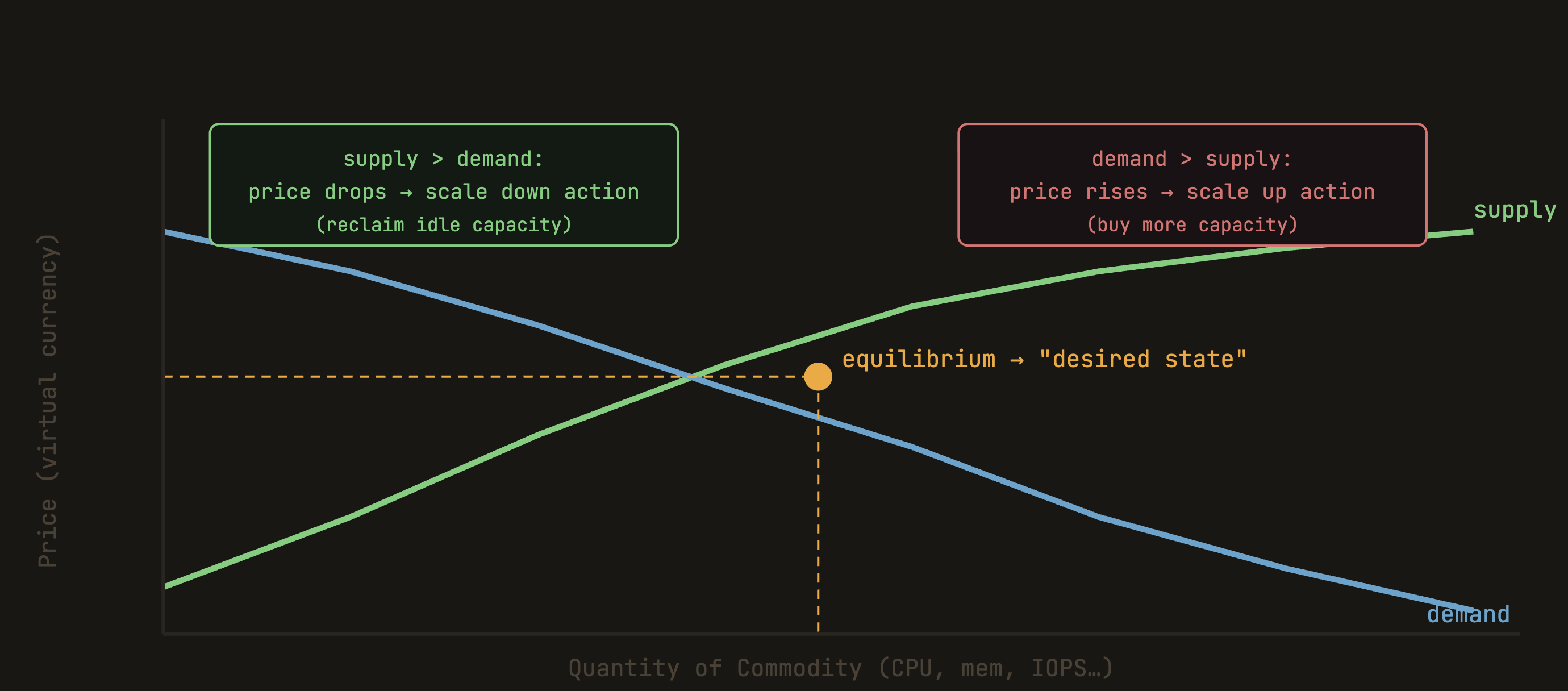
Turbonomic's founders took a completely different starting point. The whole platform is built on an economic model: your IT environment is a marketplace. Applications are buyers — they need CPU, memory, storage, network bandwidth. Infrastructure entities (hosts, datastores, cloud instance pools) are sellers. Resources are commodities with prices that fluctuate based on supply and demand. And there's a scheduling engine — inspired pretty directly by Adam Smith's concept of the invisible hand — that continuously finds the market-clearing price and recommends actions to keep the system in equilibrium.
The whole point of modeling IT as a market is that you get something reactive thresholds never give you: a globally consistent optimization signal that ripples through the entire stack simultaneously.
When I first joined VMTurbo, this model felt almost overengineered for what seemed like a simple problem. Seven years later, I think it was right. The market model is why Turbonomic can make recommendations that consider the whole stack at once — an action on a Kubernetes pod isn't evaluated in isolation, it's evaluated in terms of what it does to the VMs below it, the hosts those VMs sit on, and the storage those hosts pull from. That holistic awareness is hard to replicate with rule-based systems.

Probes: How Turbonomic Sees Everything
The supply chain model is elegant in theory. In practice, it only works if you can actually see the whole stack — and that's where the probe architecture comes in. Probes are the integration layer: modular connectors that translate the APIs of different infrastructure targets into Turbonomic's internal commodity model.
Every target type — VMware vCenter, AWS, Azure, Kubernetes, Instana, AppDynamics, NetApp, Pure Storage — has a corresponding probe that speaks its native API and converts what it sees into buyers, sellers, and commodities. The beauty of this is that once something is modeled as a commodity, the economic engine treats it the same way regardless of where it came from. A vCPU on a bare-metal host and a vCPU in an EKS cluster can participate in the same market analysis.
The probe architecture was something I found particularly well-designed. Adding a new target type meant writing a new probe without touching the core economic engine. You define your commodities, wire your probe to the discovery and monitoring cycles, and the rest of the platform just works. Dr. Banerjee's article goes deeper on the SDK side of this if you want the developer view.
How This Compares to Traditional Autoscaling
It's worth being concrete about what's actually different here, because "smarter autoscaling" is a phrase that gets thrown around a lot.
Traditional Threshold Autoscaling:
Reactive: observes metric, triggers when threshold crossed. Always lags demand.
Single-layer: typically acts on one resource type at one tier (e.g. HPA on CPU).
Metric-driven: requires a human to pick the right metric to watch and threshold to set.
Reactive to breaches: SLO violations are what triggers scaling, after the fact.
Silo'd decisions: Kubernetes team, VM team, and storage team all make separate calls.
Turbonomic Economic Model:
Continuous: market analysis runs constantly; equilibrium is the target, not a threshold.
Full-stack: a pod resize ripples through VMs, hosts, storage in the same analysis cycle.
Commodity-driven: resources are automatically priced; the engine finds the bottleneck.
SLO-driven: application SLO is a commodity constraint. Scaling prevents breach, not responds to it.
Unified optimization: one engine, one consistent signal across all infra layers.
Action Modes — The Trust Spectrum
One thing that took a lot of internal debate at Turbonomic: how much should the platform actually do on its own? The answer the product settled on was a spectrum. Every action has a mode, and operators choose where on the trust spectrum they're comfortable:
Recommend — show the action, do nothing
Manual — operator clicks to approve
Automated — platform executes on schedule
Fully Automated — continuous, no human in loop
In practice, most enterprise customers I saw deployed in a hybrid mode: fully automated for non-disruptive efficiency actions (right-sizing idle containers, moving VMs to better-utilized hosts), manual or scheduled for anything that involved disruption (live migration, scale-in). This is honestly the right call for most environments, and it reflects a reality about trust-building with automation: you start conservative and gradually expand the automation boundary as you gain confidence in the platform's decisions.
The Kubernetes story here is interesting specifically because of kubeturbo. Unlike the agentless probes for cloud platforms, kubeturbo deploys as an agent inside each cluster. It has tighter access to the K8s API and can issue pod resize and scheduling actions directly. That means the fully-automated path for Kubernetes is actually more achievable and safer than for, say, live VM migration across vSphere clusters — partly because K8s itself provides rolling update semantics that make pod-level changes less disruptive.

Where the Model Has Limits
I'd be doing the topic a disservice if I only said nice things. The economic model has some genuine rough edges that I saw up close.
The model is continuous, not predictive. The Economic Scheduling Engine finds the current equilibrium — it doesn't forecast that traffic will spike in 45 minutes. That's a meaningful gap. For workloads with known cyclical demand (the use case I covered in Part 1), pure Turbonomic ARM won't pre-warm capacity ahead of the spike; it'll respond to it. IBM addressed this partly through integration with APM tools that surface leading indicators (transaction queue depth, response time trends), which effectively shifts the signal earlier — but it's not the same as explicit time-series forecasting.
The supply chain model assumes infrastructure is the bottleneck. It's extremely good at finding infrastructure constraints and resolving them. It's less useful for application-layer performance issues — like a slow database query or a garbage collection storm — that don't manifest as resource exhaustion. The APM probes help here, but the line between "infrastructure resource problem" and "application code problem" isn't always clean, and the engine can sometimes recommend provisioning more CPU for a workload that needs a code fix.
Trust takes time to build. This one is less about the model and more about reality. I saw many deployments where teams ran Turbonomic in recommend mode for six to twelve months before enabling any automation. That's not irrational — these systems run production workloads and you need time to validate that the platform's judgment matches your operational context. But it means the ROI curve is slower than the marketing numbers imply.
The Forrester Total Economic Impact study commissioned by IBM (January 2024) put the three-year ROI at 247% for composite organizations, with savings across on-prem infrastructure consolidation, public cloud spend reduction, and IT admin productivity. Those numbers are real for mature deployments — but they assume you've trusted the platform enough to actually automate. The organizations that stayed in recommend mode indefinitely didn't get there.
What Seven Years Taught Me
The economic model, when it's working well, does something genuinely hard: it gives you a globally consistent optimization signal for a heterogeneous, multi-layer infrastructure without requiring you to manually specify what to optimize for at each level. That's a real achievement. The supply chain abstraction is elegant, and the probe architecture made it extensible in ways that pure threshold-based tools can't easily match.
But I also came out believing that the next generation of cloud resource management will need to combine the holistic, stack-aware economic model with genuine predictive capability — the kind of time-series forecasting and policy learning I covered in Part 1. Not either/or. The market model tells you what to do now. The forecasting layer tells you what to do next. Together, they cover the problem better than either alone.
In Part 3, I'll look at where the research and open-source tooling is heading on exactly that combination — ML-native scheduling for Kubernetes, and what the academic work on SLO-driven autoscaling looks like when it steps outside of commercial platforms.
*This is post #2 in a series on the state of cloud autoscaling as of 2024. Thanks to Dr. Debasish Banerjee for his IBM Developer article on Turbonomic probes, which informed parts of this post. Opinions here are my own and not those of IBM or any employer.*