
Traditional, reactive autoscaling often misses sudden demand shifts or over-provisions for safety. ML adds prediction and policy learning letting you scale before spikes, right-size capacity by workload type, and continuously improve the policy with feedback.
Why this matters now
Autoscaling is built into every major cloud, but the default signal-driven rules are reactive: they observe metrics, then adjust. That works, until it doesn’t—cold starts, long boot times, or bursty traffic can still hurt latency and cost. ML changes the game in two ways:
Forecasting (predictive autoscaling) scales ahead of demand using seasonality in historical load. AWS EC2 Auto Scaling, Google Cloud Managed Instance Groups, and Azure VM Scale Sets all expose predictive modes in production.
Policy learning (reinforcement learning, meta-RL) learns how much to scale and when—balancing SLOs and cost under uncertainty. Research shows deep RL is effective for cloud scheduling and autoscaling, with real deployments reported in industry.
What “resource allocation” really includes
Horizontal: number of replicas/VMs/containers (Kubernetes HPA, cloud instance groups). (Kubernetes)
Vertical: CPU/memory limits/requests per pod or VM; right-sizing to workload class.
Placement/scheduling: picking nodes/VM types/regions to meet SLO and cost goals.
Time-to-ready: image size, warm pools, and init times—crucial for predictive scaling to matter. (Google Cloud)
The ML toolbox (and when to use which)
Time-series forecasting (ARIMA/Prophet/LSTM/Transformers)
Use when workload follows daily/weekly cycles (e.g., consumer traffic). Forecast future QPS/CPU and scale ahead with a buffer tied to init time. Cloud predictive autoscaling features operationalize this idea.
Supervised right-sizing
Classify workloads by “shape” (CPU-bound, memory-bound, I/O-bound), then recommend requests/limits or VM flavors. Training data can come from cluster traces and cost/perf telemetry. Google’s open Borg/ClusterData traces are a common starting point.
Reinforcement learning (RL)
Learn a policy that maps cluster state → scaling action, optimizing a reward that blends SLO adherence, cost, and churn. Surveys and case studies show DRL’s promise for dynamic cloud scheduling/autoscaling.
Hybrid strategies
Forecast for “baseline” capacity + RL (or rules) for burst handling; or couple forecasting with queueing models to compute safe headroom.
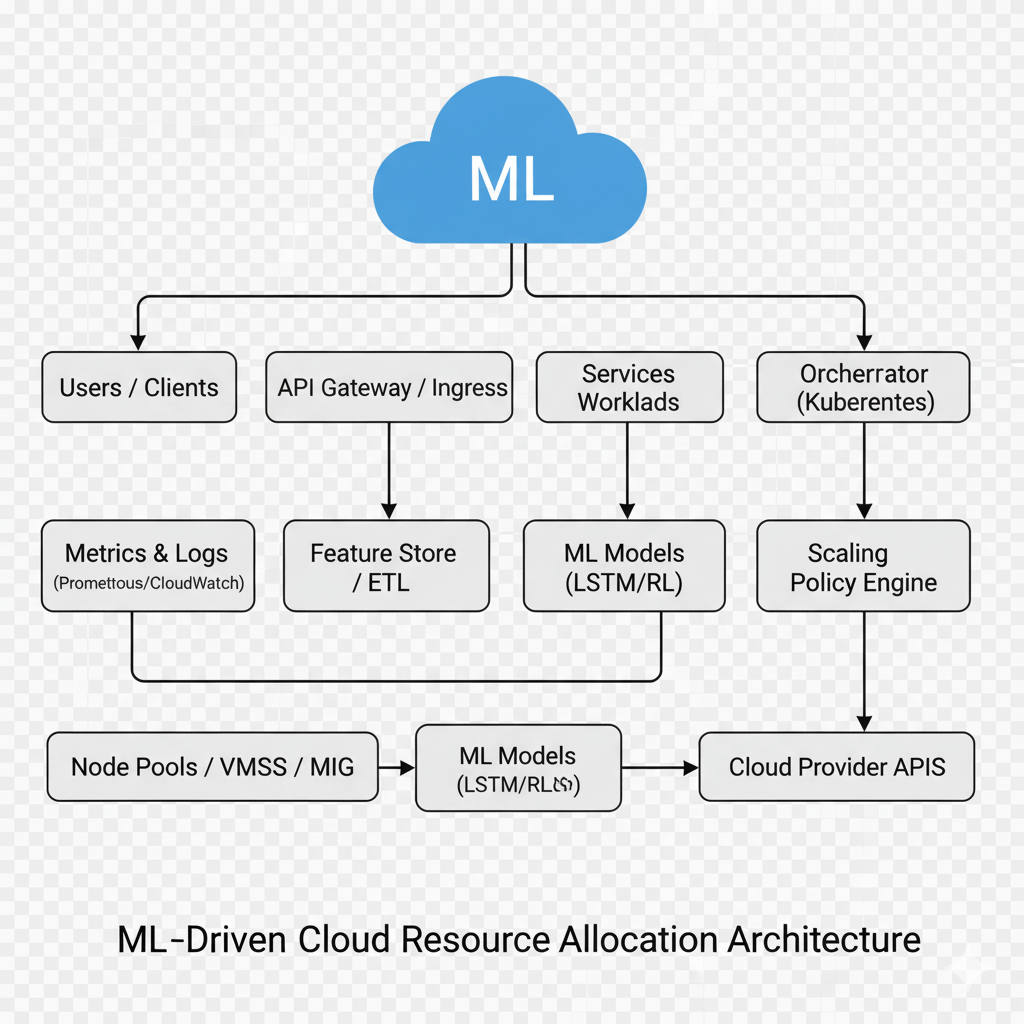
Reference architecture
The following blueprint blends platform primitives with an ML loop:
Data plane: metrics (CPU, mem, latency, queue depth), traces, and events (OOMs, throttling).
Feature/ML layer: ETL + feature store (lagged utilization, rolling volatility, time-of-day, request mix).
Models: a) forecasting model for near-term demand, b) optional RL policy for action selection.
Policy engine: turns predictions/policy outputs into concrete scaling recommendations.
Control plane: applies recommendations using native autoscalers (Kubernetes HPA/VPA/Cluster Autoscaler, cloud autoscalers with predictive modes). (Kubernetes)
Patterns by platform
Kubernetes
HPA v2 supports CPU, memory, custom, and external metrics. Use it as the actuation layer while your ML service publishes a “desired replicas” external metric. (Kubernetes+1)
Ensure a metrics pipeline (Metrics Server / custom adapters) so HPA can read signals reliably. (DigitalOcean)
AWS
- Predictive Scaling for EC2 Auto Scaling analyzes historical patterns to forecast capacity and scale proactively—especially useful when instance initialization is non-trivial. (AWS Documentation+1)
Google Cloud
- Managed Instance Groups support predictive autoscaling to spin up VMs in advance when loads follow regular cycles. (Google Cloud)
Azure
- Predictive Autoscale for VMSS reached GA and uses ML over historical CPU to pre-scale; ideal for cyclical workloads. (Microsoft Tech Community)
Data you’ll need (and what to do with it)
Historical load: request rate, CPU/memory, concurrency, queue depth; minimum 7–14 days for seasonal signals.
SLOs: latency/error budgets per endpoint or job class.
Operational context: image boot times, warm pools, rollout windows.
Feature ideas: hour-of-week, holiday flags, moving averages/volatility, traffic source mix, cache-hit rates.
Labels/targets: “replicas needed at t+Δ”, “vCPU needed for SLO at t+Δ”.
Public traces (e.g., Google ClusterData) help pre-train heuristics and validate models before going live. (GitHub+1)
Objectives & trade-offs
Resource allocation is a multi-objective problem: minimize spend and maximize SLO attainment while limiting churn (scale events). Expect a Pareto frontier rather than a single “best” policy.
Recommended reward (for RL) or loss (for forecasting+rules):
SLO penalty: heavy weight for latency > SLO or queue growth.
Cost penalty: proportional to provisioned capacity * time.
Stability term: penalize rapid scale flapping / cold starts.
A pragmatic rollout plan
Map init times: measure VM/pod “time-to-ready” and set buffers accordingly (predictive scaling helps most when init ≥ 2–3 minutes). (Google Cloud)
Start with forecasting: publish a short-horizon demand forecast and translate to “desired replicas” with headroom tied to SLO.
Close the loop: compare forecasted vs observed; auto-tune headroom; implement safeguards (max scale-in per window, cool-downs). (Google Cloud)
Pilot RL on a non-critical workload: define reward, train off-policy from logs, then run shadow mode before canarying actions. (arXiv)
Codify SLOs: alert on SLO error budget burn (not just CPU%).
Common pitfalls (and how to avoid them)
Noisy or missing signals → validate metrics freshness, reconcile scraping intervals with model cadence.
Concept drift (new releases change profile) → schedule periodic re-training and drift tests.
Cold starts dominate → add warm pools / image optimization; use predictive modes in cloud autoscalers to pre-warm. (Google Cloud)
Flapping → apply stabilization windows and scale-in controls; cap changes per window. (Google Cloud)
Further reading
Kubernetes Horizontal Pod Autoscaler (autoscaling/v2). (Kubernetes)
AWS EC2 Auto Scaling — Predictive Scaling overview. (AWS Documentation)
Google Cloud — Introducing predictive autoscaling (Compute Engine). (Google Cloud)
Azure VMSS — Predictive autoscaling GA announcement. (Microsoft Tech Community)
UCC ’23: Predictive Resource Scaling of Microservices on Kubernetes. (Diva Portal)
DRL for cloud scheduling / autoscaling (surveys). (arXiv+1)
Google ClusterData (Borg) traces + analyses. (GitHub+1)
Notes on scope
All concepts and references above are current through March 2024.